
Отже, опис вхідних даних:
transactions:
id - ідентифікатор покупця
chain - код магазину
dept - узагальнена група категорії(category), наприклад "вода".
category - категорія (напр. "газована вода")
company - ідентифікатор компанії, яка продала товар
brand - ідентифікатор бренду товару
date - дата покупки
productsize - кількість купленого товару (напр. 3 пляшки води)
productmeasure - одиниці вимірювання товару (кг, л)
purchasequantity - кількість куплених одиниць
purchaseamount - сума покупки (може бути і від'ємною, якщо покупець повернув товар пізніше)
Основна ідея колаборативної фільтрації: для кожного користувача знайти N користувачів, які максимально на нього подібні. Оце "максимально подібні" може виражатись різними метриками подібності. Вибір цих метрик залежить від того, як користувачі можуть оцінювати продукти: чисельно (напр. рейтинг) чи бінарно (купив/не купив, клікнув/не клікнув і т.д.).
У нашому випадку в якості ідентифікатора товару можна вибрати brand або комбінацію "category + company + brand". "Оцінка" продукту - сам факт покупки(тобто бінарна величина).
Для роботи з Pig нам не потрібно це перетворювати в матрицю і зберігати значення, які мають оцінку "0". Достатньо зберігати дані у вигляді:
customer_id1 product_id3
customer_id2 product_id4
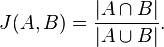
де A та B - відповідно множини брендів, куплених користувачами, подібність між якими ми хочемо обрахувати.
Перейдемо до імплементації на Pig (про встановлення можна почитати тут: http://www.gettingcirrius.com/2012/04/practical-apache-pig-recipes-round-1.html)
Для обрахування подібності між всіма користувачами нам буде потрібно дві копії даних про покупки.
-- Завантажуємо дані відповідно до схеми:
trans1 = LOAD 'transactions.csv' using PigStorage(',') AS (id:chararray, chain:chararray, dept:chararray, category:chararray, company:chararray, brand:chararray, date:chararray, productsize:int, productmeasure:chararray, purchasequantity:chararray, purchaseamount:chararray);
trans2 = LOAD 'transactions.csv' using PigStorage(',') AS (id:chararray, chain:chararray, dept:chararray, category:chararray, company:chararray, brand:chararray, date:chararray, productsize:int, productmeasure:chararray, purchasequantity:chararray, purchaseamount:chararray);
-- Відкидаємо перший рядок:
trans1 = FILTER trans1 BY id != '"id"';
trans2 = FILTER trans2 BY id != '"id"';
-- Залишаємо лише поля id та brand:
brand_1 = FOREACH trans1 GENERATE id, brand;
brand_2 = FOREACH trans2 GENERATE id, brand;
-- Видаляємо дублікати записів:
brand_1 = DISTINCT brand_1;
brand_2 = DISTINCT brand_2;
-- Для кожного користувача зберігаємо список його покупок та рахуємо загальну кількість його покупок:
grouped_brand = GROUP brand_1 BY id;
aug_brand = FOREACH grouped_brand GENERATE FLATTEN(brand_1) AS (id, brand), COUNT(brand_1) AS id_out;
grouped_brand_2 = GROUP brand_2 BY id;
aug_brand_2 = FOREACH grouped_brand_2 GENERATE FLATTEN(brand_2) AS (id, brand), COUNT(brand_2) AS id_out;
-- Робимо join по бренду:
brand_joined = JOIN aug_brand BY brand, aug_brand_2 BY brand;
-- Результат виглядає так:
-- (id1,brand,id1_purchased_amount,id2,brand,id2_purchased_amount)
-- (101496614,17286,1,103573386,17286,1)
-- (101496614,17286,1,103578365,17286,2)
-- (101496614,17286,1,103580546,17286,1)
-- (101496614,17286,1,103582976,17286,2)
-- Для користувачів знаходимо кількість спільних брендів(intersection_size) та загальну кількість брендів(added_size)
intersection = FOREACH brand_joined {
--
-- results in:
-- (X, Y, |X| + |Y|)
--
added_size = aug_brand::id_out + aug_brand_2::id_out;
GENERATE
aug_brand::id AS user1,
aug_brand_2::id AS user2,
added_size AS added_size
;
};
intersect_grp = GROUP intersection BY (user1, user2);
intersect_sizes = FOREACH intersect_grp {
--
-- results in:
-- (X, Y, |X /\ Y|, |X| + |Y|)
--
intersection_size = (double)COUNT(intersection);
GENERATE
FLATTEN(group) AS (user1, user2),
intersection_size AS intersection_size,
MAX(intersection.added_size) AS added_size -- hack, we only need this one time
;
};
-- Обраховуємо подібність між користувачами:
similarities = FOREACH intersect_sizes {
--
-- results in:
-- (X, Y, |X /\ Y|/|X U Y|)
--
similarity = (double)intersection_size/((double)added_size-(double)intersection_size);
GENERATE
user1 AS user1,
user2 AS user2,
similarity AS similarity
;
};
-- Виводимо результат:
-- DUMP similarities;
-- Відкидаємо записи, де подібність = 0 чи поле user1 = user2:
similarities = FILTER similarities BY user1 != user2 and similarity > 0;
-- Зберігаємо таблицю подібності:
STORE similarities into 'similarity_results' USING PigStorage(',');
Немає коментарів:
Дописати коментар